数据结构基础
1 Algorithm Analysis
[Definition] An algorithm is a finite set of instructions that, if followed, accomplishes a particular task. In addition, all algorithms must satisfy the following criteria.
-
Input : There are zero or more quantities that are externally supplied.
-
Output : At least one quantity is produced.
-
Definiteness : Each instruction is clear and unambiguous.
-
Finiteness : the algorithm terminates after finite number of steps
-
Effectiveness : basic enough to be carried out ; feasible
-
A program does not have to be finite. (eg. an operation system)
-
An algorithm can be described by human languages, flow charts, some programming languages, or pseudocode.
[Example] Selection Sort : Sort a set of integers in increasing order
1 | for (i = 0; i < n; i++){ |
1.1 What to Analyze
-
Machine and compiler-dependent run times.
-
Time and space complexities : machine and compiler independent.
-
Assumptions:
- instructions are executed sequentially 顺序执行
- each instruction is simple, and takes exactly one time unit
- integer size is fixed and we have infinite memory
- : the average and worst case time complexities as functions of input size
[Example] Matrix addition
1 | void add(int a[][MAX_SIZE], |
- 非对称
[Example] Iterative function for summing a list of numbers
1 | float sum (float list[], int n) |
[Example] Recursive function for summing a list of numbers
1 | float rsum (float list[], int n) |
But it takes more time to compute each step.
1.2 Asymptotic Notation()
- predict the growth ; compare the time complexities of two programs ; asymptotic(渐进的) behavior
[Definition] if there are positive constants and such that for all .(upper bound)
[Definition] if there are positive constants and such that for all .(lower bound)
[Definition] if and only if and
[Definition] if and
-
take the smallest
-
take the largest
-
Rules of Asymptotic Notation
-
If and , then
(1)
(2)
-
若是一个次多项式,则
-
for any constant (logarithms grow very slowly),无论k多小(当然要大于1),m多小(当然要大于等于0),这个式子都成立。
-


[Example] Matrix addition
1 | void add(int a[][MAX_SIZE], |
General Rules
For loops : The running time of a for loop is at most the running time of the statements inside the for loop (including tests) times the number of iterations.
Nested for loops : The total running time of a statement inside a group of nested loops is the running time of the statements multiplied by the product of the sizes of all the for loops.
Consecutive statements : These just add (which means that the maximum is the one that counts).
If/else : For the fragment
if ( Condition ) S1;
else S2;The running time is never more than the running time of the test plus the larger of the running time of S1 and S2.

Recursions :
[Example] Fibonacci number
2
3
4
5
6
7
{
if (N<=1) /*O(1)*/
return 1; /*O(1)*/
else
return Fib(N-1)+Fib(N-2);
} /*O(1)*//*T(N-1)*//*T(N-2)*/
时间复杂度: grows exponentially
空间复杂度: 递归深度是最大深度,不是所有深度之和,因为上一次用的栈已经倍释放
如果是迭代的话时间为空间为
1.3 Compare the Algorithms
[Example] 最大子序列和
Algorithm 1
1 | int MaxSubsequenceSum ( const int A[ ], int N ) |
Algotithm 2
1 | int MaxSubsequenceSum ( const int A[ ], int N ) |
Algorithm 3 Divide and Conquer 分治法
1 | static int MaxSubSum(const int A[ ], int Left, int Right) |
Algorithm 4 On-line Algorithm 在线算法
1 | int MaxSubsequenceSum( const int A[ ], int N ) |
- A[ ] is scanned once only. 扫描一次,无需存储(处理streaming data)
- 在任意时刻,算法都能对它已经读入的数据给出子序列问题的正确答案(其他算法不具有这个特性)
1.4 Logrithms in the Running Time
- 如果一个算法用常数时间将问题的大小削减为其一部分(通常是1/2),那么该算法就是的
[Example] Binary Search
1 | int BinarySearch ( const ElementType A[ ], ElementType X, int N ) |
[Example] Euclid’s Algorithm
1 | int Gcd(int M, int N) |
[Example] Efficient exponentiation
1 | long int Pow(long int X, int N) |
1.5 Checking Your Analysis
Method 1
When , check if
When , check if
When , check if
Method 2
When , check if $\lim\limits_{N\rightarrow\infty}\frac{T(N)}{f(N)}\approx C $
2 LIst, Stacks and Queues
2.1 Abstract Data Type(ADT) 抽象数据类型
[Definition] Data Type = {Objects} and {Operations}
[Definition] An Abstract Data Type(ADT) is a data type that is organized in such a way that the specification on the objects and specification of the operations on the objects are separated from the representation of the objects and the implementation on the operations.
2.2 The List ADT
- Objects : N items
- Operations
- Finding the length
- Printing
- Making an empty
- Finding
- Inserting
- Deleting
- Finding next
- Finding previous
Simple Array implementation of Lists
-
Sequential mapping 连续存储,访问快
-
Find_Kth take time.
-
MaxSize has to be estimated.
-
Insertion and Deletion not only take times, but also involve a lot of data movements which takes time. 访问要,插入要。如果要随机访问的话,肯定是线性表最快。

Query 查询
Linked Lists
-
Location of nodes may change on differrent runs.
-
Insertion 先连后断
-
Deletion 先连后释放
-
频繁malloc和free系统开销较大
-
Finding take times.
1
2
3
4
5/*Return true if L is empty*/
int IsEmpty(List L)
{
return L->Next == NULL;
}1
2
3
4
5
6/*Return true if P is the last position in list L*/
/*Parameter L is unused in this implementation*/
int IsLast(Position P, List L)
{
return P->Next == NULL;
}1
2
3
4
5
6
7
8
9
10/*Return Position of X in L; NULL if not found*/
Position Find(Element X, List L)
{
Position P;
P = L->Next;
while (P != NULL && P->Element != X) P = P->Next;
return P;
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15/*Delete first occurence of X from a list*/
/*Assume use of a header node*/
void Delete(ElementType X, List L)
{
Position P, TmpCell;
P = FindPrevious(X, L);
if (!IsLast(P, L))
{
TmpCell = P->Next;
P->Next = TmpCell->Next;
free(TmpCell);
}
}1
2
3
4
5
6
7
8
9
10
11/*If X is not found, then Next field of returned*/
/*Assumes a header*/
Position FindPrevious(ElementType X, List L)
{
Position P;
P = L;
while (P->Next != NULL && P->Next->Element != X) P = P->Next;
return P;
}1
2
3
4
5
6
7
8
9
10
11
12
13
14/*Insert (after legal position P)*/
/*Header implementation assumed*/
/*Parameter L is unused in this implementation*/
void Insert(ElementType X, List L, Position P)
{
Position TmpCell;
TmpCell = malloc(sizeof(struct Node));
if (TmpCell == NULL) FatalError("Out of space!")
TmpCell->Element = X;
TmpeCell->Next = P->Next;
P->Next = TmpCell;
}1
2
3
4
5
6
7
8
9
10
11
12
13void DeleteList(List L)
{
Position P, Tmp;
P = L->Next;
L->Next = NULL;
while (P != NULL)
{
Tmp = P->Next;
free(P);
P = Tmp;
}
}
Doubly Linked Circular Lists
-
Finding take times.

The correct answer is D.
Two Applications
- The Polynomial ADT
-
Objects :
-
Operations :
-
Finding degree
-
Addition
-
Subtraction
-
Multiplication
-
Differentiation
-
-
[Representation 1]
1
2
3
4typedef struct {
int CoeffArray [ MaxDegree + 1 ] ;
int HighPower;
} *Polynomial ;1
2
3
4
5
6
7
8/*将多项式初始化为零*/
void ZeroPolynomial(Polynomial Poly)
{
int i;
for(i = O; i <= MaxDegree; i++)
Poly->CoeffArray[ i ] = O;
Poly->HighPower = O;
}1
2
3
4
5
6
7
8
9
10
11/*两个多项式相加*/
void AddPolynomial(const Polynomial Poly1, const Polynomial Poly2, Polynomial PolySum)
{
int i;
ZeroPolynomial(PolySum);
PolySum->HighPower = Max(Poly1->HighPower, Poly2->HighPower);
for (i = PolySum->HighPower; i >= O; i--)
PolySum->CoeffArray[ i ] = Poly1->CoeffArray[ i ] + Poly2->CoeffArray[ i ];
}1
2
3
4
5
6
7
8
9
10
11
12
13
14void MultPolynomial(const Polynomial Poly1, const Polynomial Poly2, Polynomial PolyProd)
{
int i, j;
ZeroPolynomial (PolyProd);
PolyProd->HighPower = Poly1->HighPower + Poly2->HighPower;
if(PolyProd->HighPower > MaxDegree)
Error("Exceeded array size");
else
for(i = O; i <= Poly1->HighPower; i++)
for(j = O; j <= Poly2->HighPower; j++)
PolyProd->CoeffArray[ i + j ] += Poly1->CoeffArray[ i ] * Poly2->CoeffArray[ j ];
} -
[Representation 2]
1
2
3
4
5
6
7typedef struct poly_node *poly_ptr;
struct poly_node{
int Coefficient; /* assume coefficients are integers */
int Exponent;
poly_ptr Next;
};
typedef poly_ptr a; /* nodes sorted by exponent */- 只存储非零项
- Multilists
Cursor Implementation of Linked Lists(no pointer)

2.3 The Stack ADT
- Last-In-First-Out (LIFO)
- Objects : A finite ordered list with zero or more elements.
- Operations :
- IsEmpty
- CreatStack
- DisposeStack
- MakeEmpty
- Push
- Top
- Pop
- A Pop(or Top) on an empty stack in an error in the stack ADT.
- Push on a full stack is an implementation error but not an ADT error.
- 如果考那种算数式子的入栈出栈的话,符号是不用入栈的;但是如果题目要求用栈实现算式从中序变成post就是需要的,而且左右括号也是算进栈的空间的!
Linked List Implementation (with a header node)

-
The calls to malloc and free are expensive. Simply keep another stack as a recycle bin.
1
2
3
4int IsEmpty(Stack S)
{
return S->Next == NULL;
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18Stack CreateStack(void)
{
Stack S;
S = malloc(sizeof(struct Node));
if (S == NULL)
Fatal Error("Out of space!");
S->Next == NULL;
MakeEmpty(S);
return S;
}
void MakeEmpty(Stack S)
{
if (S == NULL)
Error("Must use CreateStack first");
else
while(!IsEmpty(S)) Pop(S);
}1
2
3
4
5
6
7
8
9
10
11
12
13void Push(ElementType X, Stack S)
{
PtrToNode TmpCell;
TmpCell = malloc(sizeof(struct Node));
if (TmpCell == NULL)
Fatal Error("Out of space!") ;
else
{
TmpCell->Element = X;
TmpCe11->Next = S->Next;
S->Next = TmpCell;
}
}1
2
3
4
5
6
7ElementType Top(Stack S)
{
if(!IsEmpty(S))
return S->Next->Element;
Error("Empty stack") ;
return O; /* Return value used to avoid warning*/
}1
2
3
4
5
6
7
8
9
10
11
12void Pop(Stack s)
{
PtrToNode FirstCell;
if(IsEmpty(S))
Error("Empty stack") ;
else
{
FirstCe11 = S->Next;
S->Next = S->Next->Next;
free(FirstCe11);
}
}
Array Implementation of Stacks
1 | struct StackRecord { |
-
The stack model must be well encapsulated(封装). That is, no part of your code, except for the stack routines, can attempt to access the Array or TopOfStack variable.
-
Error check must be done before Push or Pop (Top).
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16Stack CreateStack(int MaxElements)
{
Stack S;
if(MaxElements < MinStackSize)
Error("Stack size is too small") ;
S = malloc(sizeof(struct StackRecord));
if (S == NULL)
Fatal Error("Out of space!!!") ;
S->Array = malloc(sizeof(ElementType) * MaxElements) ;
if(S->Array = NULL)
Fatal Error("Out of space!!!");
S->Capacity = MaxElements;
MakeEmpty(S) ;
return S;
}1
2
3
4
5
6
7
8void DisposeStack(Stack S)
{
if(S != NULL)
{
free(S->Array);
free(S);
}
}1
2
3
4int IsEmpty(Stack S)
{
return S->TopOfStack == EmptyTOS;
}1
2
3
4void MakeEmpty(Stack S)
{
S->TopOfStack = EmptyTOS;
}1
2
3
4
5
6
7void Push(ElementType X, Stack S)
{
if (IsFull(S))
Error("Full stack");
else
S->Array[ ++S->TopOfStack ] = X;
}1
2
3
4
5
6
7ElementType Top(Stack S)
{
if(! IsEmpty(S))
return S->Array[ S->TopOfStack ];
Error("Empty stack") ;
return O; /* Return value used to avoid warning*/
}1
2
3
4
5
6
7void Pop(Stack S)
{
if(IsEmpty(S))
Error("Empty stack") ;
else
S->TopOfStack--;
}1
2
3
4
5
6
7ElementType TopAndPop(Stack S)
{
if(!Is Empty(S))
return S->Array[ S->TopOfStack-- ];
Error("Empty stack");
return O; /* Return value used to avoid warnin */
}
Application
-
Balancing Symbols
检查括号是否平衡
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15Algorithm {
Make an empty stack S;
while (read in a character c) {
if (c is an opening symbol)
Push(c, S);
else if (c is a closing symbol) {
if (S is empty) { ERROR; exit; }
else { /* stack is okay */
if (Top(S) doesn’t match c) { ERROR, exit; }
else Pop(S);
} /* end else-stack is okay */
} /* end else-if-closing symbol */
} /* end while-loop */
if (S is not empty) ERROR;
} -
Postfix Evaluation 后缀表达式
-
Infix to Postfix Conversion
- 读到一个操作数时立即把它放到输出中
- 读到一个操作符时从栈中弹出栈元素直到发现优先级更低的元素为止,再将操作符压入栈中,注意最后一次右括号是不用入栈的,把两括号里面的通通弹出去就行了,括号是不用显示在输出中的,但是也占据栈的空间。
- The order of operands is the same in infix and postfix.
- Operators with higher precedence appear before those with lower precedence.
- Never pop a ’(‘ from the stack except when processing a ‘)’.
- When ‘(’ is not in the stack, its precedence is the highest; but when it is in the stack, its precedence is the lowest.
- Exponentiation associates right to left.
-
Function Calls (System Stack)

Note : Recursion can always be completely removed. Non recursive programs are generally faster than equivalent recursive programs. However, recursive programs are in general much simpler and easier to understand.
2.4 The Queue ADT
- First-In-First-Out (FIFO)
- Objects : A finite ordered list with zero or more elements.
- Operations :
- IsEmpty
- CreatQueue
- DisposeQueue
- MakeEmpty
- Enqueue
- Front
- Dequeue
Array Implementation of Queues
1 | struct QueueRecord { |
Circular Queue :


- The maximum capacity of this queue is 5.
- PPT中队列的初始化front = -1, rear = 0代表队列为空;在循环队列中如果不做处理,front = rear的时候就不知道是已经满了还是只有一个元素,一般的操作是在front前空一格元素,在初始化的时候把front弄成n - 1。
- 当然传统方法是把rear弄成队列末元素的下一个空格的下标的,这样初始化就变成了front = rear = 0. 判断是否满队可以用
(front + 1) % maxSize == rear来判断;队列的长度可以用(rear - front + maxSize) % maxSize来计算。
Note : Adding a Size field can avoid wasting one empty space to distinguish “full” from “empty”.
3 Trees
3.1 Preliminaries
[Definition] A tree is a collection of nodes. The collection can be empty; otherwise, a tree consists of (1) a distinguished node r, called the root; (2) and zero or more nonempty (sub)trees, each of whose roots are connected by a directed edge from r.
-
Subtrees must not connect together. Therefore every node in the tree is the root of some subtree.
-
There are N-1 edges in a tree with N nodes
Terminologies
- degree of a node : 结点的子树个数
- degree of a tree : 结点的度的最大值
- parent : 有子树的结点
- children : the roots of the subtrees of a parent
- siblings : children of the same parent
- leaf(terminal node) : a node with degree 0(no children)
- path from to : a unique sequence of nodes such that is the parent of for
- length of path : 路径上边的条数
- depth of : 从根结点到结点的路径的长度()
- height of : 从结点到叶结点的最长路径的长度()
- height/depth of a tree : 根结点的高度/最深的叶结点的深度
- ancestors of a node : 从此结点到根结点的路径上的所有结点
- descendants of a node : 此结点的子树中的所有结点
List Representation
-
The size of each node depends on the number of branches.

The correct answer is T.
FirstChild-NextSibling Representation

-
The representation is not unique since the children in a tree can be of any order.
他也没说左边那个一定是FirstChild,所以是完全可以不唯一的。
-
注意如果一棵普通的T通过这个变换变成了BT,那么两者的前序遍历不变,且BT的中序遍历和T的后序遍历一样。
3.2 Binary Trees
[Definition] A binary tree is a tree in which no node can have more than two children.
Tree Traversals (visit each node exactly once)
-
Preorder Traversal
1
2
3
4
5
6
7
8
9void preorder( tree_ptr tree )
{
if( tree )
{
visit ( tree );
for (each child C of tree )
preorder ( C );
}
} -
Postorder Traversal
1
2
3
4
5
6
7
8
9void postorder( tree_ptr tree )
{
if( tree )
{
for (each child C of tree )
postorder ( C );
visit ( tree );
}
} -
Levelorder Traversal
1
2
3
4
5
6
7
8
9
10void levelorder( tree_ptr tree )
{
enqueue ( tree );
while (queue is not empty)
{
visit ( T = dequeue ( ) );
for (each child C of T )
enqueue ( C );
}
} -
Inorder Traversal
1
2
3
4
5
6
7
8
9void inorder( tree_ptr tree )
{
if( tree )
{
inorder ( tree->Left );
visit ( tree->Element );
inorder ( tree->Right );
}
}Iterative Program :
1
2
3
4
5
6
7
8
9
10
11
12
13
14void iter_inorder( tree_ptr tree )
{
Stack S = CreateStack( MAX_SIZE );
for ( ; ; )
{
for ( ; tree; tree = tree->Left )
Push ( tree, S );
tree = Top ( S );
Pop( S );
if ( !tree ) break;
visit ( tree->Element );
tree = tree->Right;
}
}
注意:通过前序遍历和后序遍历在一定情况下是可以建树的!!别想当然以为给出的树会是三角形的。。。很有可能推出来就是一条线。。。
Threaded Binary Trees
-
A full binary tree with nodes has links, and of them are NULL.
-
注意满二叉树(Full Binary Tree)是完全满的树,完全二叉树(Complete Binary Tree)是先填上层再填下层,同一层内先填左边后填右边的二叉树,不要搞混了。
-
Replace the NULL links by “threads” which will make traversals easier.
注意,这里如果左边或者右边已经都有非空指针了就不需要线索了。线索二叉树只是利用原来为空的结点进行一番操作。而且如果没有前驱或后继,这根指向NULL的线索是不能省去的!!

Rules :
- If Tree->Left is null, replace it with a pointer to the inorder predecessor(中序前驱) of Tree.
- If Tree->Right is null, replace it with a pointer to the inorder successor(中序后继) of Tree.
- There must not be any loose threads. Therefore a threaded binary tree must have a head node of which the left child points to the first node.
1 | typedef struct ThreadedTreeNode *PtrToThreadedNode; |
-
线索化的实质就是将二叉链表中的空指针改为指向前驱或后继的线索。由于前驱和后继信息只有在遍历该二叉树时才能得到,所以,线索化的过程就是在遍历的过程中修改空指针的过程。看清楚他要的是什么遍历的线索二叉树,一般没说的话默认中序的。

-
In a tree, the order of children does not matter. But in a binary tree, left child and right child are different.
Properties of Binary Trees
The maximum number of nodes on level is .
The maximum number of nodes in a binary tree of depth is .
For any nonempty binary tree, where is the number of leaf nodes and is the number of nodes of degree 2.
推导(degree更多的同理):
树的总顶点数,其中代表有个degree的顶点数;
每个顶点上方下方都有degree条边,即边的数量,又有树中恒存在,两个 式子等一下就行了。
感觉考试的时候必考一道判断或者选择。
3.3 Binary Search Trees
[Definition] A binary search tree is a binary tree. It may be empty. If it is not empty, it satisfies the following properties:
- 每个结点有一个互不不同的值
- 若左子树非空,则左子树上所有结点的值均小于根结点的值
- 若右子树非空,则右子树上所有结点的值均大于根结点的值
- 左、右子树也是是一棵二叉查找树
- 给出互不相同的元素个数,能得到的不同的BST个数符合卡特兰数,通项公式为,其中这样。
- 假设在BST中同时有5,6,7三个数,6并不一定会是5、7两个点的parent,有可能5、7两个点分属两个不同的子树,6只是它们的ancestor.
ADT
- Objects : A finite ordered list with zero or more elements.
- Operations :
- SearchTree MakeEmpty( SearchTree T )
- Position Find( ElementType X, SearchTree T )
- Position FindMin( SearchTree T )
- Position FindMax( SearchTree T )
- SearchTree Insert( ElementType X, SearchTree T )
- SearchTree Delete( ElementType X, SearchTree T )
- ElementType Retrieve( Position P )
Implementations
-
Find
1
2
3
4
5
6
7
8
9
10
11
12Position Find( ElementType X, SearchTree T )
{
if ( T == NULL )
return NULL; /* not found in an empty tree */
if ( X < T->Element ) /* if smaller than root */
return Find( X, T->Left ); /* search left subtree */
else
if ( X > T->Element ) /* if larger than root */
return Find( X, T->Right ); /* search right subtree */
else /* if X == root */
return T; /* found */
}- where is the depth of X
Iterative program :
1
2
3
4
5
6
7
8
9
10
11
12
13Position Iter_Find( ElementType X, SearchTree T )
{
while ( T )
{
if ( X == T->Element )
return T; /* found */
if ( X < T->Element )
T = T->Left; /*move down along left path */
else
T = T-> Right; /* move down along right path */
} /* end while-loop */
return NULL; /* not found */
} -
FindMin
1
2
3
4
5
6
7
8Position FindMin( SearchTree T )
{
if ( T == NULL )
return NULL; /* not found in an empty tree */
else
if ( T->Left == NULL ) return T; /* found left most */
else return FindMin( T->Left ); /* keep moving to left */
} -
FindMax
1
2
3
4
5
6
7Position FindMax( SearchTree T )
{
if ( T != NULL )
while ( T->Right != NULL )
T = T->Right; /* keep moving to find right most */
return T; /* return NULL or the right most */
} -
Insert
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22SearchTree Insert( ElementType X, SearchTree T )
{
if ( T == NULL ) /* Create and return a one-node tree */
{
T = malloc( sizeof( struct TreeNode ) );
if ( T == NULL )
FatalError( "Out of space!!!" );
else
{
T->Element = X;
T->Left = T->Right = NULL;
}
} /* End creating a one-node tree */
else /* If there is a tree */
if ( X < T->Element )
T->Left = Insert( X, T->Left );
else
if ( X > T->Element )
T->Right = Insert( X, T->Right );
/* Else X is in the tree already; we'll do nothing */
return T; /* Do not forget this line!! */
}- 内存越界后不会马上报错,在下一次free或malloc时会失败
- Handle duplicated keys
-
Delete
- Delete a leaf node : Reset its parent link to NULL
- Delete a degree 1 node : Replace the node by its single child
- Delete a degree 2 node : 用左子树最大值结点或右子树最小值结点替换
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25SearchTree Delete( ElementType X, SearchTree T )
{
Position TmpCell;
if ( T == NULL ) Error( "Element not found" );
else if ( X < T->Element ) /* Go left */
T->Left = Delete( X, T->Left );
else if ( X > T->Element ) /* Go right */
T->Right = Delete( X, T->Right );
else /* Found element to be deleted */
if ( T->Left && T->Right ) { /* Two children */
/* Replace with smallest in right subtree */
TmpCell = FindMin( T->Right );
T->Element = TmpCell->Element;
T->Right = Delete( T->Element, T->Right ); } /* End if */
else
{ /* One or zero child */
TmpCell = T;
if ( T->Left == NULL ) /* Also handles 0 child */
T = T->Right;
else if ( T->Right == NULL )
T = T->Left;
free( TmpCell );
} /* End else 1 or 0 child */
return T;
}Note : If there are not many deletions, then lazy deletion may be employed: add a flag field to each node, to mark if a node is active or is deleted. Therefore we can delete a node without actually freeing the space of that node. If a deleted key is reinserted, we won’t have to call malloc again.
-
Average-Case Analysis
- The average depth over all nodes in a tree is on the assumption that all trees are equally likely.
- 将个元素存入二叉搜索树,树的高度将由插入序列决定

The correct answer is A.
4 Priority Queues (Heaps)
4.1 ADT Model
- Objects :A finite ordered list with zero or more elements.
- Operations :
- PriorityQueue Initialize( int MaxElements );
- void Insert( ElementType X, PriorityQueue H );
- ElementType DeleteMin( PriorityQueue H );
- ElementType FindMin( PriorityQueue H );
4.2 Implementations
Array
-
Insertion — add one item at the end ~
-
Deletion — find the largest / smallest key ~
remove the item and shift array ~
Linked List
-
Insertion — add to the front of the chain ~
-
Deletion — find the largest / smallest key ~
remove the item ~
- Never more deletions than insertions
Ordered Array
-
Insertion — find the proper position ~
shift array and add the item ~
-
Deletion — remove the first / last item ~
Ordered Linked List
-
Insertion — find the proper position ~
add the item ~
-
Deletion — remove the first / last item ~
Binary Search Tree
- Both insertion and deletion will take only.
- Only delete the the minimum element, always delete from the left subtrees.
- Keep a balanced tree
- But there are many operations related to AVL tree that we don’t really need for a priority queue.
4.3 Binary Heap
Structure Property
[Definition] A binary tree with nodes and height is complete if its nodes correspond to the nodes numbered from to in the perfect binary tree of height .
-
A complete binary tree of height has between and nodes.
-
-
Array Representation : BT[n + 1] ( BT[0] is not used)

[Lemma]
1 | PriorityQueue Initialize( int MaxElements ) |
Heap Order Property
[Definition] A min tree is a tree in which the key value in each node is no larger than the key values in its children (if any). A min heap is a complete binary tree that is also a min tree.
- We can declare a max heap by changing the heap order property.
Basic Heap Operations
-
Insertion
1
2
3
4
5
6
7
8
9
10
11
12
13/*H->Element[ 0 ] is a sentinel that is no larger than the minimum element in the heap.*/
void Insert( ElementType X, PriorityQueue H )
{
int i;
if ( IsFull( H ))
{
Error( "Priority queue is full" );
return;
}
for ( i = ++H->Size; H->Elements[ i/2 ] > X; i /= 2 )
H->Elements[ i ] = H->Elements[ i/2 ]; /*Percolate up, faster than swap*/
H->Elements[ i ] = X;
} -
DeleteMin
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24ElementType DeleteMin( PriorityQueue H )
{
int i, Child;
ElementType MinElement, LastElement;
if ( IsEmpty( H ) )
{
Error( "Priority queue is empty" );
return H->Elements[ 0 ];
}
MinElement = H->Elements[ 1 ]; /*Save the min element*/
LastElement = H->Elements[ H->Size-- ]; /*Take last and reset size*/
for ( i = 1; i * 2 <= H->Size; i = Child ) /*Find smaller child*/
{
Child = i * 2;
if (Child != H->Size && H->Elements[Child+1] < H->Elements[Child])
Child++;
if ( LastElement > H->Elements[ Child ] ) /*Percolate one level*/
H->Elements[ i ] = H->Elements[ Child ];
else
break; /*Find the proper position*/
}
H->Elements[ i ] = LastElement;
return MinElement;
}
Other Heap Operations
- 查找除最小值之外的值需要对整个堆进行线性扫描
-
DecreaseKey — Percolate up
-
IncreaseKey — Percolate down
-
Delete
-
BuildHeap
将N 个关键字以任意顺序放入树中,保持结构特性,再执行下滤
1
2for (i = N/2; i > 0; i--)
PercolateDown(i);[Theorem] For the perfect binary tree of height containing nodes, the sum of the heights of the nodes is .

感觉这道题错了好几次了,如果每两层之间应该是需要两次,因为子节点之间需要比一次,当前结点与子节点的小的那个又要比一次,就要次比较了,把代进去,得到的结果是次比较。
4.4 Applications of Priority Queues
Heap Sort
查找一个序列中第k小的元素
The function is to find the K-th smallest element in a list A of N elements. The function BuildMaxHeap(H, K) is to arrange elements H[1] … H[K] into a max-heap.
1 | ElementType FindKthSmallest ( int A[], int N, int K ) |
4.5 -Heaps — All nodes have children
Note :
- DeleteMin will take comparisons to find the smallest child. Hence the total time complexity would be .
- *2 or /2 is merely a bit shift, but *d or /d is not.
- When the priority queue is too large to fit entirely in main memory, a d-heap will become interesting.


正确答案是4,注意“in the process”
5 The Disjoint Set
5.1 Equivalence Relations
[Definition] A relation R is defined on a set S if for every pair of elements (a, b), a, b S, a R b is either true or false. If a R b is true, then we say that a is related to b.
[Definition] A relation, ~, over a set, S, is said to be an equivalence relation over S if it is symmetric, reflexive, and transitive over S.
[Definition] Two members x and y of a set S are said to be in the same equivalence class if x ~ y.
5.2 The Dynamic Equivalence Problem
-
Given an equivalence relation ~, decide for any a and b if a ~ b
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16Algorithm: (Union/Find)
{
/* step 1: read the relations in */
Initialize N disjoint sets;
while ( read in a ~ b )
{
if ( !(Find(a) == Find(b)) ) /*Dynamic(on-line)*/
Union the two sets;
} /* end-while */
/* step 2: decide if a ~ b */
while ( read in a and b )
if ( Find(a) == Find(b) )
output( true );
else
output( false );
} -
Elements of the sets :
-
Sets :
-
Operations :
- Union( ) = Replace and by
- Find( ) = Find the set which contains the element
5.3 Basic Data Structure
Union( )
-
Make a subtree of , or vice versa, that is to set the parent pointer of one of the roots to the other root.
-
Implementation 1 :

-
Implementation 2 :
-
The elements are numbered from 1 to N, hence they can be used as indices of an array.
-
S[ element ] = the element’s parent
-
Note : S[ root ] = 0 and set name = root index
-
数组初始化全部为0
1
2
3
4void SetUnion(DisjSet S, SetType Rt1, SetType Rt2)
{
S[Rt2] = Rt1;
} -
Find( )
-
Implementation 1 :

-
Implementation 2 :
1
2
3
4
5SetType Find(ElementType X, DisjSet S)
{
for ( ; S[X]>0; X=S[X]);
return X;
}
Analysis
- Union and find are always paired. Thus we consider the performance of a sequence of union-find operations.

1 | Algorithm using union-find operations: |
- Worst case :
5.4 Smart Union Algorithms
Union-by-Size
-
Always change the smaller tree
-
S[Root] = -size, initialized to be -1
-
[Lemma] Let T be a tree created by union-by-size with N nodes, then .
Proved by induction. Each element can have its set name changed at most times. 这玩意很喜欢考判断题。
-
Time complexity of Union and Find operations is now .
1 | /* Assumes Rootl and Root2 are roots*/ |
Union-by-Height
- Always change the shallow tree
- 保证所有的树的深度最多是
1 | /* Assumes Rootl and Root2 are roots*/ |
5.5 Path Compression
- 从X到Root的路径上的每一个结点都使它的父结点变成Root
1 | SetType Find( ElementType X, DisjSet S ) |
1 | SetType Find( ElementType X, DisjSet S ) |
- Note : Not compatible with union-by-height since it changes the heights. Just take “height” as an estimated rank.
- 比如说要U(3,4),先得去找3的ancester,在找的过程中把路过的点全都接到ancester上,然后对4也这么干,然后把4的ancester接到3的ancester上即可。
- 选择题千万要看清楚他问的是depth还是size的最小值,而且要看清楚他选项里有没有写大,如果是Union by size的话他最优情况下得到的深度是有可能出现1的,但是如果带了大就是了,可以参考上面的公式。
5.6 Worst Case for Union-by-Rank and Path Compression
[Lemma] Let be the maximum time required to process an intermixed sequence of finds and unions, then for some positive constants and .
-
Ackermann’s Function
-
(inverse Ackermann function) = number of times the logarithm is applied to until the result . 就是说,阿克曼函数的反函数增长极其缓慢,一般不会超过4;这个带路径压缩的按秩合并的时间复杂度也是很低的。一般而言不会超过,基本上就是M的常数倍。
5.7 Conclusion
一共有五种算法,注意看清题设
-
No smart union
-
Union-by-size
-
Union-by-height
-
Union-by-size + Path Compression
-
Union-by-height + Path Compression
6 Graph Algorithms
6.1 Definitions
- where = graph, = finite nonempty set of vertices, and = finite set of edges.
Undirected graph
- = the same edge.
Directed graph(diagraph)

Restrictions
- Self loop is illegal. 不能自己对自己成环。
- Multigraph is not considered. 两点之间不能有很多同向的条边。
Complete graph
- A graph that has the maximum number of edges.

Adjacent


Subgraph
Path
- Path() from to = such that belong to
Length of a path
- number of edges on the path
Simple path
- are distinct.
Cycle
- simple path with
Connected
- and in an undirected are connected if there is a path from to (and hence there is also a path from to )
- An undirected graph is connected if every pair of distinct and are connected
(Connected) Component of an undirected G
- the maximal connected subgraph
Tree
- a graph that is connected and acyclic(非循环的)
DAG
- a directed acyclic graph
Strongly connected directed graph G
- For every pair of and in , there exist directed paths from to and from to . 双向连接
- If the graph is connected without direction to the edges, then it is said to be weakly connected. 对应的无向图连通
Strongly connected component
- the maximal subgraph that is strongly connected
Degree
-
number of edges incident to v
-
For a directed G, we have in-degree and out-degree.
-
Given G with vertices and edges, then
6.2 Representation of Graphs
Adjacency Matrix

Note : If G is undirected, then adj_mat[][] is symmetric. Thus we can save space by storing only half of the matrix.

-
This representation wastes space if the graph has a lot of vertices but very few edges.
-
To find out whether or not is connected, we’ll have to examine all edges. In this case and are both .
Adjacency Lists
- Replace each row by a linked list. 每个指向与它相邻的那几个(要考虑边的方向)

Note : The order of nodes in each list does not matter.
- For undirected , = heads + nodes = ptrs + ints. 如果是无向图的话一条边会被冗余地存两次
- Degree(i) = number of nodes in graph[i](if is undirected)
- 为统计入度可以引入反邻接表(inverse adjacency list),比如原来1->2,现在在2后面接个1
- of examine =

Adjacency Multilists

- graph[i] 是顶点结点,后面的是表结点。graph[i] 指向第一条跟该节点有关的边;表结点的结构体中前两个参数 ivex 和 jvex 分别表示该结点表示的边两端的顶点在数组中的位置下标,它们下面的 ilink 和 jlink 指向下一条与当前端点相邻的边,比如01这条边的1就没有下一条边了。
- Sometimes we need to mark the edge after examine it, and then find the next edge.
Weighted Edges
- adj_mat [ i ] [ j ] = weight
- adjacency lists / multilists : add a weight field to the node
6.3 Topological Sort
AOV Network
- digraph in which represents activities and represents precedence relations
- Feasible AOV network must be a directed acyclic graph.
- is a predecessor前驱 of = there is a path from to
- is an immediate predecessor of = . Then is called a successor后继(immediate successor) of
Partial order
- a precedence relation which is both transitive and irreflexive
Note : If the precedence relation is reflexive, then there must be an such that is a predecessor of . That is, must be done before is started. Therefore if a project is feasible, it must be irreflexive.
[Definition] A topological order is a linear ordering of the vertices of a graph such that, for any two vertices, , , if is a predecessor of in the network then precedes in the linear ordering.
Note : The topological orders may not be unique for a network. 拓扑序不一定唯一!
1 | /*Test an AOV for feasibility, and generate a topological order if possible*/ |
每次都要去重新找有哪些点indegree为0,拿出来了之后把相邻点indegree减一,直到所有点都拿出来。
1 | /*Improvment:Keep all the unassigned vertices of degree 0 in a special box (queue or stack)*/ |
把每次找到的indegree为0的点入队,然后在减别的点的indegree时顺便把减完为0的点入队,下一次把队头的元素弹出来作为下一个结点,TopNum[] 中记录了每个结点在拓扑序中的下标。时间复杂度:第一步是把所有点检查一遍,第二步这个while循环是把所有边检查了一遍。相当于,优化了一下。
6.4 Shortest Path Algorithms
Given a digraph , and a cost function for .
The length of a path from source to destination is (also called weighted path length).
Single-Source Shortest-Path Problem
Given as input a weighted graph, , and a distinguished vertex , find the shortest weighted path from to every other vertex in .
Note: If there is no negative-cost cycle, the shortest path from to is defined to be zero.
Unweighted Shortest Path
- Breadth-first search 广度优先遍历 所有边都等权的最短路径问题
Implementation :
- Table[ i ].Dist ::= distance from to /* initialized to be except for */
- Table[ i ].Known ::= 1 if is checked; or 0 if not
- Table[ i ].Path ::= for tracking the path /* initialized to be 0 */
1 | void Unweighted( Table T ) |
先找周围一圈的点(CurrDist = 1),再对这每个点找周围一圈的点(CurrDist = 2,当然是要在Known = false的点中找),用 T[W] 记录下 W 点前一个点 V 的下标。
The worst case :
 $$
T(N)=O(|V|^2)
$$
Improvement :
$$
T(N)=O(|V|^2)
$$
Improvement :
1 | void Unweighted( Table T ) |
每次取队列中的点,把这个点变成Known,更新周围所有的unknown的点的距离和路径数组,然后把涉及到的点就按照字典序放进队中(因为是无权的,每个先后不用管),之后就直接从队中dequeue出来重复做。
Weighted Shorted Path
Dijkstra’s Algorithm
- Let S = { and ’s whose shortest paths have been found }
- For any , define distance [ u ] = minimal length of path { }. If the paths are generated in non-decreasing order, then :
- the shortest path must go through only
- Greedy Method : is chosen so that distance[ u ] = min{ | distance[ w ] } (If is not unique, then we may select any of them)
- if distance[] < distance[] and add into , then distance [ ] may change. If so, a shorter path from to must go through and distance [ ] = distance [ ] + length(< , >).
1 | typedef int Vertex; |
1 | void InitTable(Vertex Start, Graph G, Table T) |
1 | /*Print shortest path to V after Dijkstra has run*/ |
1 | void Dijkstra( Table T ) |
每次把非known的最短结点拿出来弄成Known,然后更新相邻结点距离。一共要遍历次,每次遍历都要在差不多个点中找最小的。然后在更新的时候,一共需要把所有边的权都考虑一遍。
Implementation 1
- Simply scan the table to find the smallest unknown distance vertex.——
- Good if the graph is dense 稠密矩阵的时候好
Implementation 2
-
堆优化
-
Keep distances in a priority queue and call
DeleteMinto find the smallest unknown distance vertex.——用堆排序来放结点距离。 -
更新的处理方法
-
Method 1 :
DecreaseKey—— -
Method 2 : insert W with updated Dist into the priority queue
Must keep doing
DeleteMinuntil an unknown vertex emergesbut requires
DeleteMinwith|E|space
-
-
Good if the graph is sparse
Improvements
- Pairing heap
- Fibonacci heap
Graphs with Negative Edge Costs
1 | void WeightedNegative( Table T ) |
Note : Negative-cost cycle will cause indefinite loop,而且很有可能算上负数了之后,那些已经Known了的边会存在更短的路径
Acyclic Graphs
- If the graph is acyclic, vertices may be selected in topological order since when a vertex is selected, its distance can no longer be lowered without any incoming edges from unknown nodes.
- and no priority queue is needed.
AOE(Activity on Edge) Networks



方法解析
先根据拓扑序+迪杰斯特拉算法求出各个结点的最早发生时间EC(别被这个“最早”迷惑了,实际上求的是max,就是最早可以发生的时间),然后根据汇点的EC逆拓扑序求出每个点的最晚发生时间LC(同样的别被“最晚”迷惑了,这里求的是min,相当于对求max,也就是说正向传播和反向传播都是在求max),然后两个点之间的松弛时间可以用上面这个公式求出,松弛时间都是0的这条路就是关键路径。
All-Pairs Shortest Path Problem
- For all pairs of and ( ), find the shortest path between.
Method 1
- Use single-source algorithm for times.
- , works fast on sparse graph.
Method 2
- 动态规划
- algorithm given in Chapter 10, works faster on dense graphs.
6.5 Network Flow Problems(最大流问题)

- Determine the maximum amount of flow that can pass from to .
Note : Total coming in () = Total going out () where
A Simple Algorithm
- 流图表示算法的任意阶段已经达到的流,开始时的所有边都没有流,算法终止时包含最大流
- 残余图(residual graph)表示对于每条边还能添加上多少流,的边叫做残余边(residual edge)
Step 1 : Find any path from to in , which is called augmenting path(增长通路).
Step 2 : Take the minimum edge on this path as the amount of flow and add to .
Step 3 : Update and remove the 0 flow edges.
Step 4 : If there is a path from to in then go to Step 1, or end the algorithm.
- Step 1中初始选择的路径可能使算法不能找到最优解,贪心算法行不通
A solution
-
allow the algorithm to undo its decisions
-
For each edge with flow in , add an edge with flow in .
就是说,每次操作时,在残差图中,不仅要用逆向边的值抵掉(一部分)原来边的值,还要将这条逆向边再写一遍(或者加到参差图上的与之同向的边上),就像这里面中间这两条边。

Note : The algorithm works for with cycles as well.
[Proposition] If the edge capabilities are rational numbers, this algorithm always terminate with a maximum flow.
Analysis
-
An augmenting path can be found by an unweighted shortest path algorithm.
-
where is the maximum flow.
-
Always choose the augmenting path that allows the largest increase in flow
- 对Dijkstra算法进行单线(single-line)修改来寻找增长通路
- 为最大边容量
- 条增长通路将足以找到最大流,对于增长通路的每次计算需要时间
-
Always choose the augmenting path that has the least number of edges
- 使用无权最短路算法来寻找增长路径
Note :
- If every has either a single incoming edge of capacity 1 or a single outgoing edge of capacity 1, then time bound is reduced to .
- The min-cost flow problem is to find, among all maximum flows, the one flow of minimum cost provided that each edge has a cost per unit of flow.
6.6 Minimum Spanning Tree
[Definition] A spanning tree of a graph is a tree which consists of and a subset of
Note :
- The minimum spanning tree is a tree since it is acyclic, the number of edges is
- It is minimum for the total cost of edges is minimized.
- It is spanning because it covers every vertex.
- A minimum spanning tree exists if is connected.
- Adding a non-tree edge to a spanning tree, we obtain a cycle.
Greedy Method
Make the best decision for each stage, under the following constrains :
- we must use only edges within the graph
- we must use exactly edges
- we may not use edges that would produce a cycle
-
Prim’s Algorithm
- 在算法的任一时刻,都可以看到一个已经添加到树上的顶点集,而其余顶点尚未加到这棵树中,和迪杰斯特拉算法很像,一般用在邻接表的情况。
- 算法在每一阶段都可以通过选择边,使得的值是所有 在树上但不在树上的边的值中的最小者(就是离已生成的树最近的点),而找出一个新的顶点并把它添加到这棵树中
-
Kruskal’s Algorithm
-
连续地按照最小的权选择边,,并且当所选的边不产生环时就把它作为取定的边,思路比较简单,但是里面可能要涉及到并查集。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15void Kruskal( Graph G )
{
T = { };
while ( T contains less than |V|-1 edges && E is not empty )
{
choose a least cost edge (v, w) from E; /*DeleteMin*/
delete (v, w) from E;
if ( (v, w) does not create a cycle in T )
add (v, w) to T; /*Union/Find*/
else
discard (v, w);
}
if ( T contains fewer than |V|-1 edges )
Error( “No spanning tree” );
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27void Kruskal(Graph G)
{
int EdgesAccepted;
DisjSet S;
PriorityQueue H;
Vertex U, V;
SetType Uset, Vset;
Edge E;
Initialize(S);
ReadGraphIntoHeapArray(G, H);
BuildHeap(H);
EdgesAccepted = 0;
while(EdgesAccepted < NumVertex-1)
{
E = DeleteMin(H); /*E = (U,V)*/
Uset = Find(U, S);
Vset = Find(V, S);
if(Uset != Vset)
{
/*Accept the edge*/
EdgesAccepted++;
SetUnion(S, USet, VSet);
}
}
}
千万注意最小生成树是权和最小,不是迪杰斯特拉算法的路径长度最小!如果要考虑阿克曼函数的话,应该是的复杂度,其中是逆阿克曼函数。
-
6.7 Applications of Depth-First Search
1 | /*a generalization of preorder traversal*/ |
Undirected Graphs
1 | void ListComponents(Graph G) |
Biconnectivity
- is an articulation point(关键点) if has at least 2 connected components.
- is a biconnected graph(双连通图) if is connected and has no articulation points.
- A biconnected component is a maximal biconnected subgraph.


Note : No edges can be shared by two or more biconnected components. Hence is partitioned by the biconnected components of .
Finding the biconnected components of a connected undirected :
Use depth first search to obtain a spanning tree of
- Depth first number() 先序编号
- Back edges(背向边or回边) = tree and is an ancestor of . 生成树里没有但是原图里有。
Note : If is an ancestor of , then .
Find the articulation points in
The root is an articulation point if it has at least 2 children.
如果根有两个孩子那它肯定是关键点。
Any other vertex is an articulation point if has at least 1 child, and it is impossible to move down at least 1 step and then jump up to ‘s ancestor
有孩子,而且这个点往下走1步或多步之后没法通过回边跳回到这个结点的祖先结点
注意:回边不能跨子树,否则后一个子树就可以直接在前一个子树的DFS的时候一起做掉了,相当于应该接在前一个子树下面。


-
对于深度优先搜索生成树上的每一个顶点,计算编号最低的顶点,称之为,可以理解为这个点往下走之后能通过 back edge 回到的最小的下标数。
-
选择题很有可能考多少条边多少个点最多/最少有多少连通分支,举个例子100个点12条边,如果要考虑最少的情况,则尽可能地用边去消耗点,比如每两个点连一条边,这样是一组,一共消耗了24个点,产生了12个连通分量,剩下76个点,这样就是88个连通分支;考虑最多的情况,就是尽可能地用点去消耗边,尽量去构造边最多的完全图,比如5个点的完全图是条边,这样还差2条边,只能再加上1个点,这样用了6个点就消耗了12条边,剩下94个点,这样就是95个连通分支。
1 | /*Assign Num and compute Parents*/ |
1 | /*Assign Low; also check for articulation points*/ |
1 | void FindArt(Vertex V) |
Euler Circuits
[Proposition] An Euler circuit is possible only if the graph is connected and each vertex has an even degree. 度全是偶数有欧拉回路。
[Proposition] An Euler tour is possible if there are exactly two vertices having odd degree. One must start at one of the odd-degree vertices. 只有两个度是奇数有欧拉路线。
Note:
- The path should be maintained as a linked list.
- For each adjacency list, maintain a pointer to the last edge scanned.
- ,判断是否是割点和寻找欧拉回路的复杂度都是这个
7 Sorting
7.1 Preliminaries
1 | void X_Sort (ElementType A[], int N) |
- N must be a legal integer.
- Assume integer array for the sake of simplicity.
- ‘>’ and ‘<’ operators exist and are the only operations allowed on the input data.
- Consider internal sorting only. The entire sort can be done in main memory.
- 一般的排序都是基于比较的,像桶排序之类的是基于分类的;基于比较的排序算法在最坏情况下的最优时间复杂度为.
7.2 Insertion Sort
1 | void Insertion(ElementType A[], int N) |
-
The worst case : Input A[ ] is in reverse order
-
The best case : Input A[ ] is in sorted order
-
注意区分选择和插入,选择是遍历后面所有的,然后选最小的和当前位置的交换;插入是选择局部最小的插到已处理序列的合适位置。
7.3 A Lower Bound for Simple Sorting Algorithms
[Definition] An inversion(逆序对) in an array of numbers is any ordered pair having the property that but
-
Swapping two adjacent elements that are out of place removes exactly one inversion.
-
where is the number of inversions in the original array.
[Theorem] The average number of inversions in an array of distinct numbers is
[Theorem] Any algorithm that sorts by exchanging adjacent elements requires time on average
7.4 Shellsort

-
Define an increment sequence
-
Define an -sort at each phase for
-
最后一轮就是Insertion Sort
Note : An -sorted file that is then -sorted remains -sorted.
Shell’s Increment Sequence(希尔增量序列)
1 | void Shellsort( ElementType A[ ], int N ) |
- 注意到,如果增量取8、4、2、1这种不互质的,有的时候小增量根本就没啥用,所以要谨慎考虑增量序列。
- [Theorem] The worst-case running time of Shellsort, using Shell’s increments, is .
Hibbard’s Increment Sequence
- 就是1、3、7这种的增量
- [Theorem] The worst-case running time of Shellsort, using Hibbard’s increments, is .
Conjecture
- Sedgewick’s best sequence is in which the terms are either of the form or
. and .
Conclusion
- Shellsort is a very simple algorithm, yet with an extremely complex analysis.
- It is good for sorting up to moderately large input (tens of thousands).
7.5 Heapsort
Algorithm1
1 | void Heapsort( int N ) |
- The space requirement is doubled. 就用普通堆的话,Delete出来的要放在另一个数组里面。
Algorithm2
1 | void Heapsort( ElementType A[ ], int N ) |
- 建一个大顶堆,然后把对顶和堆底换一下,相当于是把最大的换到最后面,然后把刚刚换上来的下滤一下维持大顶堆的性质(记得把堆的大小减一),等堆的大小为零的时候说明已经排序结束。
- [Theorem] The average number of comparisons used to heapsort a random permutation of N distinct items is . 注意建堆的比较次数和建堆后再排序的比较次数是不一样的!!
Note : Although Heapsort gives the best average time, in practice it is slower than a version of Shellsort that uses Sedgewick’s increment sequence.
7.6 Mergesort(归并排序)
1 | void MSort( ElementType A[ ], ElementType TmpArray[ ], int Left, int Right ) |
-
先分后治。先用MSort函数把这一段数分成很多小段,然后每段里面再用Merge函数进行排序。

-
If a TmpArray is declared locally for each call of Merge, then .
1 | /*Lpos = start of left half, Rpos = start of right half*/ |
Analysis
- (这个和第一节课推的那个很像)
Note : Mergesort requires linear extra memory, and copying an array is slow. It is hardly ever used for internal sorting, but is quite useful for external sorting.
7.7 Quicksort
- the fastest known sorting algorithm in practice
Algorithm
1 | void Quicksort( ElementType A[ ], int N ) |
- The pivot is placed at the right place once and for all.
- 要研究的问题是如何选取枢纽元(主元)和如何划分
Picking the Pivot
A Wrong Way
-
Pivot = A[ 0 ],The worst case : A[ ] is presorted, quicksort will take time to do nothing
取了A[0]作为主元,但是已经A已经排好了,相当于浪费了时间,本来用就差不多了。
A Safe Maneuver
- Pivot = random select from A[ ],但是随机数生成是很昂贵的。
Median-of-Three Partitioning
- Pivot = median(left, center, right),从前中后三个数中选个中位数。
- Eliminates the bad case for sorted input and actually reduces the running time by about 5%.
Partitioning Strategy
- 当在的左边时,我们将右移,移过那些小于枢纽元的元素,并将左移,移过那些大于枢纽元的元素
- 当和停止时,指向一个大元素而指向一个小元素,如果在的左边,那么将这两个元素互换
- 重复该过程直到和彼此交错为止
- 划分的最后一步是将枢纽元与所指向的元素交换
- 如果和遇到等于枢纽元的键值,就让和都停止,因为若都不停止
- There will be many dummy swaps, but at least the sequence will be partitioned into two equal-sized subsequences. 如果出现很多相同元素的话可能会出现很多无意义的交换。
Small Arrays
- Quicksort is slower than insertion sort for small 小数组就用插排.
- Cutoff when gets small and use other efficient algorithms (such as insertion sort).
Implementation
1 | void Quicksort( ElementType A[ ], int N ) |
1 | /* Return median of Left, Center, and Right */ |
1 | void Qsort( ElementType A[ ], int Left, int Right ) |
Note : If set i = Left+1 and j = Right-2, there will be an infinite loop if A[i] = A[j] = pivot.
Analysis
-
is the number of the elements in . 不同数据的快慢看得就是主元选择是否合适,如果选的很极端的话肯定慢,如果选在中间的话就相对较快。
-
The Worst Case
-
The Best Case
-
The Average Case
- Assume the average value of for any is
Quickselect
- 查找第最大(最小)元
1 | /*Places the kth sma11est element in the kth position*/ |

正确答案是D。每次run都要排一个pivot,但是如果第一次的pivot选在了最大或最小的地方,第二次的pivot就只有一个了,否则应该有两个,也就是说两轮之后的pivot总共有三个(在特殊情况下只有两个)。比如C里面2、28、32都可以作为pivot,是没问题的;D里面只有12、32两个pivot,应该是不对的。
7.8 Sorting Large Structures
- Swapping large structures can be very much expensive.
- Add a pointer field to the structure and swap pointers instead – indirect sorting. Physically rearrange the structures at last if it is really necessary.
- Table Sort
7.9 A General Lower Bound for Sorting
[Theorem] Any algorithm that sorts by comparisons only must have a worst case computing time of . 用决策树可以证明。
- When sorting distinct elements, there are different possible results.
- Thus any decision tree must have at least leaves.
- If the height of the tree is , then
- Since and
- Therefore
7.10 Bucket Sort

1 | Algorithm |
7.11 Radix Sort(基数排序)


- where is the number of passes, is the number of elements to sort, and is the number of buckets.
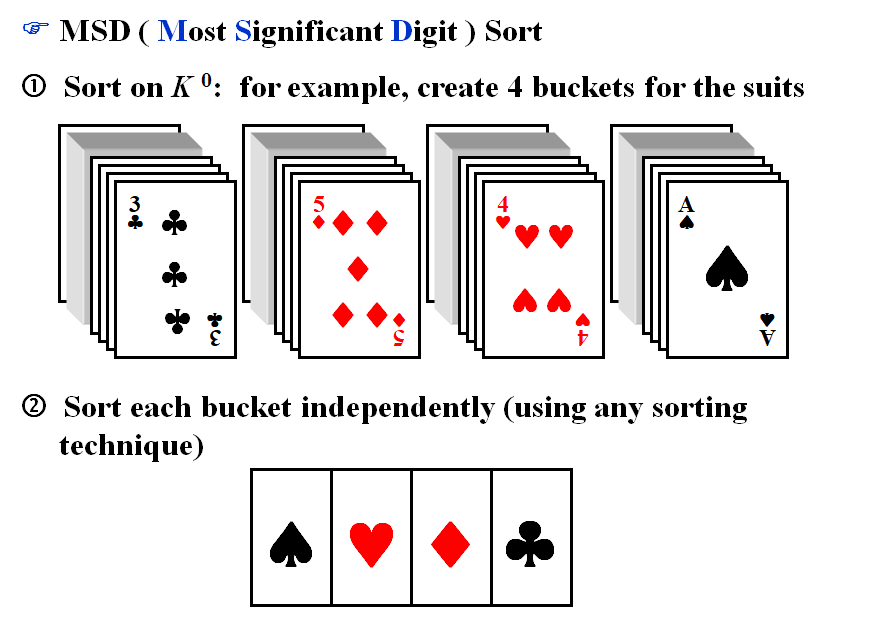
MSD(Most Significant Digit) Sort and LSD(Least Significant Digit) Sort



-
稳定的排序算法:冒泡排序、插入排序、归并排序、基数排序
-
不稳定的排序算法:选择排序、快速排序、希尔排序、堆排序
牢牢记住,归并、基数这两个看起来就比较稳,快排和希尔看起来就不稳

-
这里需要注意:希尔排序的平均情况是跟增量的选择有关系的,不能简单地认为是,如果增量取得不好会退化成最差情况,只是某个序列时候的最好情况;其最好情况是能达到的,这是快排、堆排和归并做不到的;堆排、归并的三个量是一样的,都是;快排和希尔的最坏能达到。
-
空间上这张表里面写得有点问题,堆排和希尔不用额外的空间,是四个里面最好的;归并要开额外开一个的空间来暂时放已经排好的子列(先要分治再合并,合并的时候只能将两个并成一个),是四个里面最差的;快排自己就能排,但是需要递归实现,递归实现就要靠系统调用栈,深度是,处于中间。
相当于是希尔 = 堆排 < 快排 < 归并
-
归并是学到现在的唯一一种可以作为外部排序的排序算法。
8 Hashing
8.1 General Idea

Symbol Table ADT
- Objects : A set of name-attribute pairs, where the names are unique
- Operations :
- SymTab Create(TableSize)
- Boolean IsIn(symtab, name)
- Attribute Find(symtab, name)
- SymTab Insert(symtab, name, attr)
- SymTab Delete(symtab, name)
Hash Tables

- A collision occurs when we hash two nonidentical identifiers into the same bucket.
- An overflow occurs when we hash a new identifier into a full bucket.
8.2 Hash Function
- must be easy to compute and minimize the number of collisions.
- should be unbiased. For any and any , we have that . Such kind of a hash function is called a uniform hash function.
8.3 Separate Chaining(链地址法)
- keep a list of all keys that hash to the same value
- 链地址法的装填因子loading density和开放地址法是一样的,就是key的数量除以表长;但是其平均查找时间的算法和开放地址法的不一样。

而开放地址法就是把每个元素的查找次数加起来:

1 | struct ListNode; |
Create an empty table
1 | HashTable InitializeTable( int TableSize ) |
Find a key from a hash table
1 | Position Find ( ElementType Key, HashTable H ) |
Insert a key into a hash table
1 | void Insert ( ElementType Key, HashTable H ) |
Note : Make the TableSize about as large as the number of keys expected (i.e. to make the loading density factor $\lambda\approx$1).
8.4 Open Addressing(开放地址法)
- find another empty cell to solve collision(avoiding pointers)
1 | Algorithm: insert key into an array of hash table |
Note : Generally . 一般装填因子在0.5以下。
Linear Probing
- is a linear function of , such as . 千万注意,是在原来的的基础上加的,别直接在的基础上加。
- 逐个探测每个单元(必要时可以绕回)以查找出一个空单元
- 使用线性探测的预期探测次数对于插入和不成功的查找来说大约是,对于成功的查找来说是,随着变大会越来越差。
- Cause primary clustering : any key that hashes into the cluster will add to the cluster after several attempts to resolve the collision.
注意:有的时候它给的除数和TableSize是完全不一样的两个数,别mod的时候想当然认为是一样的。
Quadratic Probing
- is a quadratic function of , such as .
[Theorem] If quadratic probing is used, and the table size is prime, then a new element can always be inserted if the table is at least half empty. 考判断题!!

这个证明的意思就是说,最后如果和的和或者差要能整除TableSize,但是,而且它们的取值范围摆在那边,这就可以推得两次探测的肯定是不一样的。
Note : If the table size is a prime of the form , then the quadratic probing can probe the entire table. 能探测到表的每一个位置。
真正实操的时候一般是每次直接上 $ 2 \cdot i - 1$的
1 | HashTable InitializeTable(int TableSize) |
1 | Position Find(ElementType Key, HashTable H) |
1 | void Insert(ElementType Key, HashTable H) |
Note :
- Insertion will be seriously slowed down if there are too many deletions intermixed with insertions.
- Although primary clustering is solved, secondary clustering occurs, that is, keys that hash to the same position will probe the same alternative cells.
Double Hashing(双重哈希)
- make sure that all cells can be probed
- with a prime smaller than TableSize, will work well.
- 比如说冲突了,那么就上,如果说键值不同的话,一般来说一次应该可以解决了;如果反复插入同一个键值,可能就要把翻倍了 了。
Note :
- If double hashing is correctly implemented, simulations imply that the expected number of probes is almost the same as for a random collision resolution strategy.
- Quadratic probing does not require the use of a second hash function and is thus likely to be simpler and faster in practice.
8.5 Rehashing(二次哈希)
- Build another table that is about twice as big. (尽量选择一个比两倍大的而且是质数的数)
- Scan down the entire original hash table for non-deleted elements.
- Use a new function to hash those elements into the new table.
- When to rehash
- As soon as the table is half full
- When an insertion fails
- When the table reaches a certain load factor
Note : Usually there should have been N/2 insertions before rehash, so O(N) rehash only adds a constant cost to each insertion. However, in an interactive system, the unfortunate user whose insertion caused a rehash could see a slowdown.
1 | HashTable Rehash(HashTable H) |